
ICASSP 2026 | 实验室发布声纹识别领域最新创新成果
2026国际声学、语音与信号处理会议(ICASSP)将于 5 月在西班牙巴塞罗那举行。作为 IEEE 信号处理学会的旗舰学术年会,ICASSP 是全球规模最大、覆盖最全面的声学、语音、音频与信号处理领域顶级会议,自 1976 年创办以来始终引领行业前沿,每年吸引全球数万名学者交流最新研究成果。
由实验室作为唯一机构单位投稿的首篇论文《ENHANCING SPEAKER VERIFICATION WITH LAYER-WISE MIXTURE-OF-EXPERTS ON PRE-TRAINED MODELS》(论文第一作者:李宜爽,通讯作者:甘伟豪,由余意、涂永峰共同完成),凭借创新性的技术方案与扎实的实验验证,成功被会议正式录用,团队将于会议期间进行成果汇报与学术交流。

文章提出一种将语音预训练模型(PTMs)与混合专家(MoE)结合的说话人验证方法。据我们所知,这是首次将 MoE 系统性应用于说话人验证任务。
研究背景
说话人验证(Speaker Verification,SV)旨在判断两段语音是否来自同一说话人。深度学习推动了 SV 架构演进,TDNN、ResNet、ECAPA-TDNN 等模型显著提升了性能。近年来,Wav2vec 2.0、HuBERT、UniSpeech-SAT、WavLM 等语音预训练模型(PTMs)通过自监督与大规模无标注数据学习到更强的通用表征,逐渐作为前端特征提取器接入下游 SV 网络。
进一步地,研究者们提出加权求和、注意力融合、多尺度融合等跨层聚合策略,以更充分利用PTM不同 Transformer 层中的说话人信息,提升系统性能。然而,PTMs 在真实场景中仍受域差异影响(如设备、噪声、口音、性别等因素导致的分布变化),单一模型难以兼顾多种条件,泛化受限。
为此,实验室研究团队在每个 Transformer 层后引入混合专家(MoE)模块,通过门控与动态路由实现输入自适应的域特征选择,并结合级联残差门控(CRG)保留浅层声学线索、交叉注意力融合(CAF)沿层维度动态整合多层特征,从而兼顾鲁棒性与判别性。基于上述设计,本文提出基于PTM+MoE 的 SV 框架并用实验充分验证了其有效性。
核心要点
文章所提出方法的整体框架如图 1 所示:首先,CNN 编码器对输入语音波形进行下采样并提取低层声学特征;随后,多层 Transformer 生成层级化的通用表示。针对每一层表示,插入 MoE 模块以实现域自适应特征选择,并通过级联残差门控将浅层信息逐步传播至更深层;同时,引入交叉注意力融合模块完成跨层表征融合。最终,将融合后的特征输入下游 SV 网络(包括 ECAPA-TDNN 框架、注意力统计池化与全连接层),生成最终的说话人嵌入。
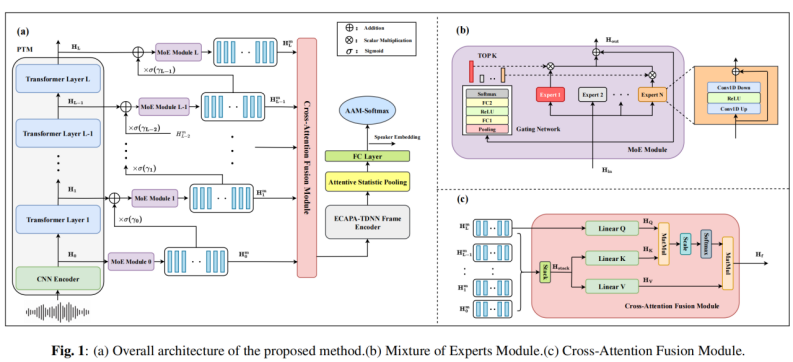
实验验证
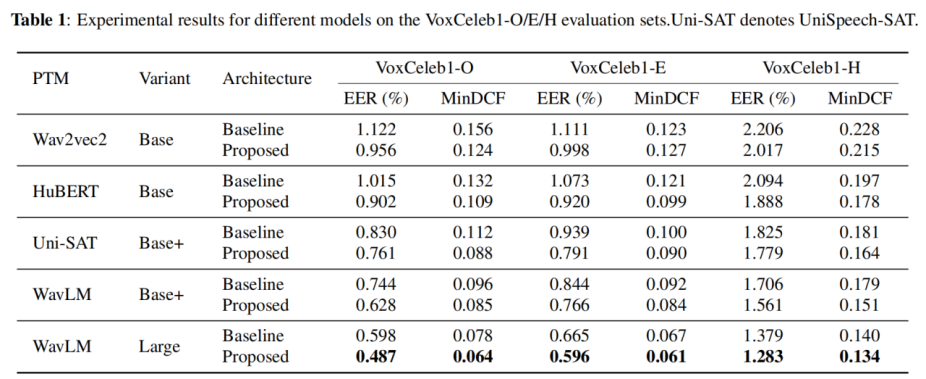
主要实验结果如表 1 所示:在五种 PTM 变体上,文章所提出方法在VoxCeleb1 三种测试集上均取得稳定提升。以 WavLM Base+ 作为前端为例,相比基线系统,本方法在 VoxCeleb1-O / E / H 上的相对等错误率(EER)降幅分别达到 15.6%、9.2% 和 8.5%。
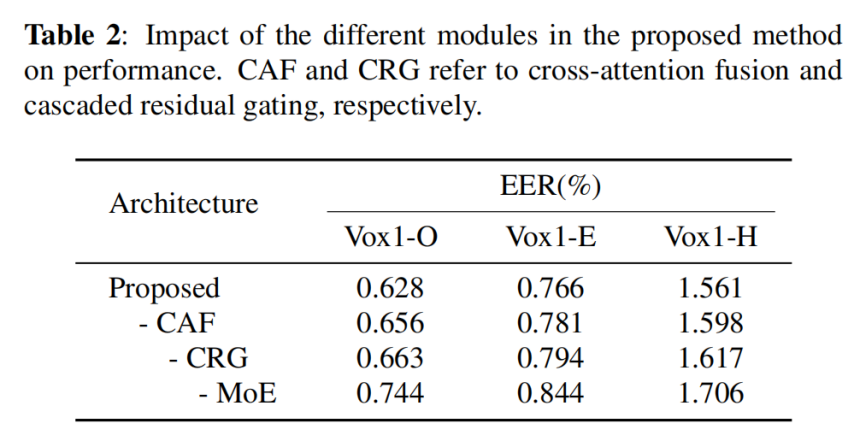
为进一步分析各模块的贡献,文章进行了相关消融实验。如表 2 所示,MoE、CAF 与 CRG 三个模块均能带来正向收益:当分别移除 CAF 或 CRG 时,EER 逐步上升;进一步移除 MoE 模块后,EER 显著上升。这表明 MoE 在面向域的特征选择中发挥了关键作用,是整体性能提升的重要来源。
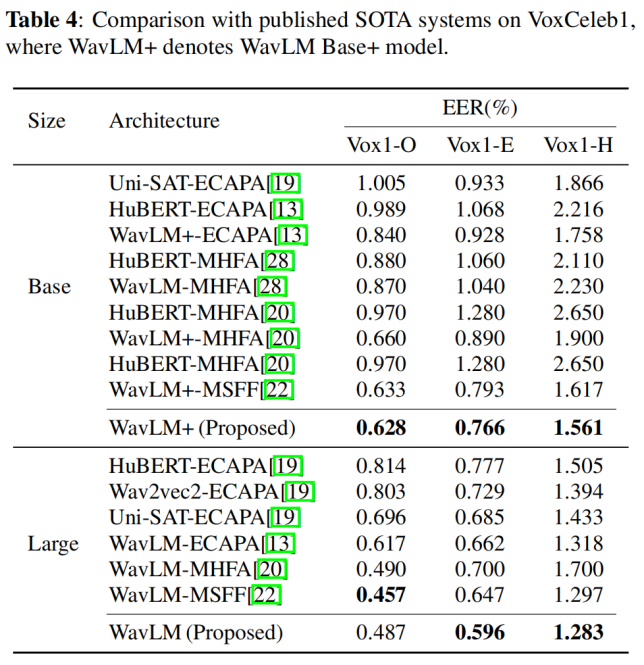
最后,研究团队将所提出方法与现有基于 PTM 的最优说话人验证系统进行对比。表 4 的结果显示,无论采用 Base 还是 Large 版本的 PTM,本方法均取得了与当前 SOTA 系统相当的性能,进一步验证了方法的有效性与鲁棒性。
应用场景
说话人识别技术已广泛嵌入智能手机、车载系统、笔记本电脑与智能家居,承担语音身份认证职能,显著提升设备与服务的安全性。
在金融场景中,它用于银行交易与远程支付的客户核验,降低冒用与欺诈风险。
在互联网应用中,常与在线会议和客服平台深度集成,用于自动识别发言者、关联账户与权限,优化用户体验与业务流程。
刑侦领域可借助该技术比对声纹、锁定嫌疑人并提供侦查线索,同时在监控系统中实现身份检出与自动标注。
于音频信息管理方面,它支持对广播新闻、会议记录和电话通话等语音数据的按人检索与高效归档。并且,作为自动语音识别的前端模块,在多说话人与重叠语音场景中能够精准区分说话人,显著提升转写准确性。
马栏山音视频实验室作为音视频领域的重要科研平台,始终聚焦技术创新与产业融合。此次成果入选 ICASSP 2026,是实验室在声学、语音、音频与信号处理领域科研实力的又一重要体现,也彰显了团队在国际学术舞台上的竞争力。
未来,实验室将持续支持前沿技术研究,推动该论文相关成果的落地转化,为相关产业方向的高质量发展提供技术支撑,助力我国音视频产业在全球产业链中占据更核心的地位。