
声源定向技术
在日常生活中,我们往往不假思索地依靠听觉来确定声音的方向,这项看似简单的技能背后,其实隐藏着一项极具价值的技术——声源定位技术。
该技术不仅帮助我们在自然环境中精确定位声音的来源,在科技领域也同样发挥着关键作用,广泛应用于语音识别、机器人导航、安防监控、会议系统以及智能音箱等多个方面,成为这些应用中不可或缺的一部分。
声源定位技术的基本原理
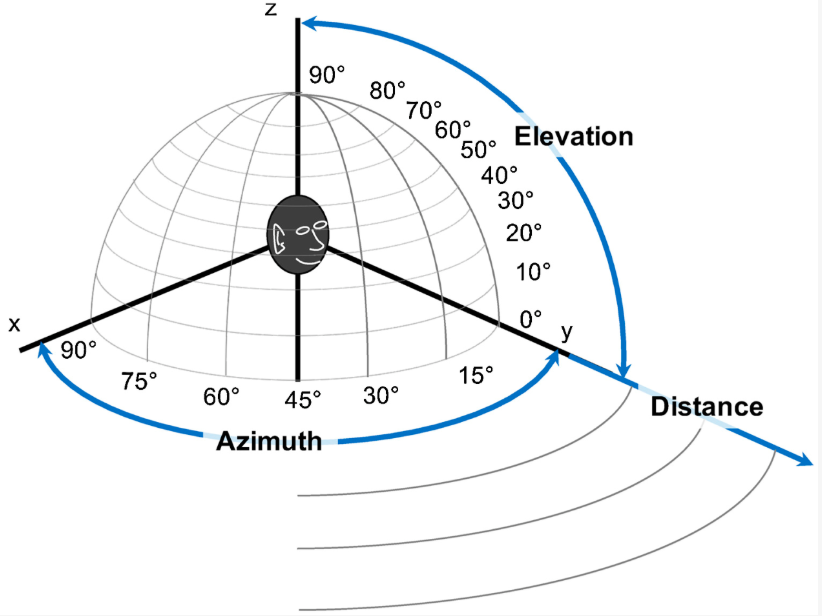
声源定位技术的基本原理是在不同位置布置多个麦克风来捕捉声音信号,并利用声波到达各麦克风的时间差异(即时间延迟)。通过算法分析这些时间差,可以精确计算出声源的方位角、俯仰角和距离。
基于相对时延估计的方法
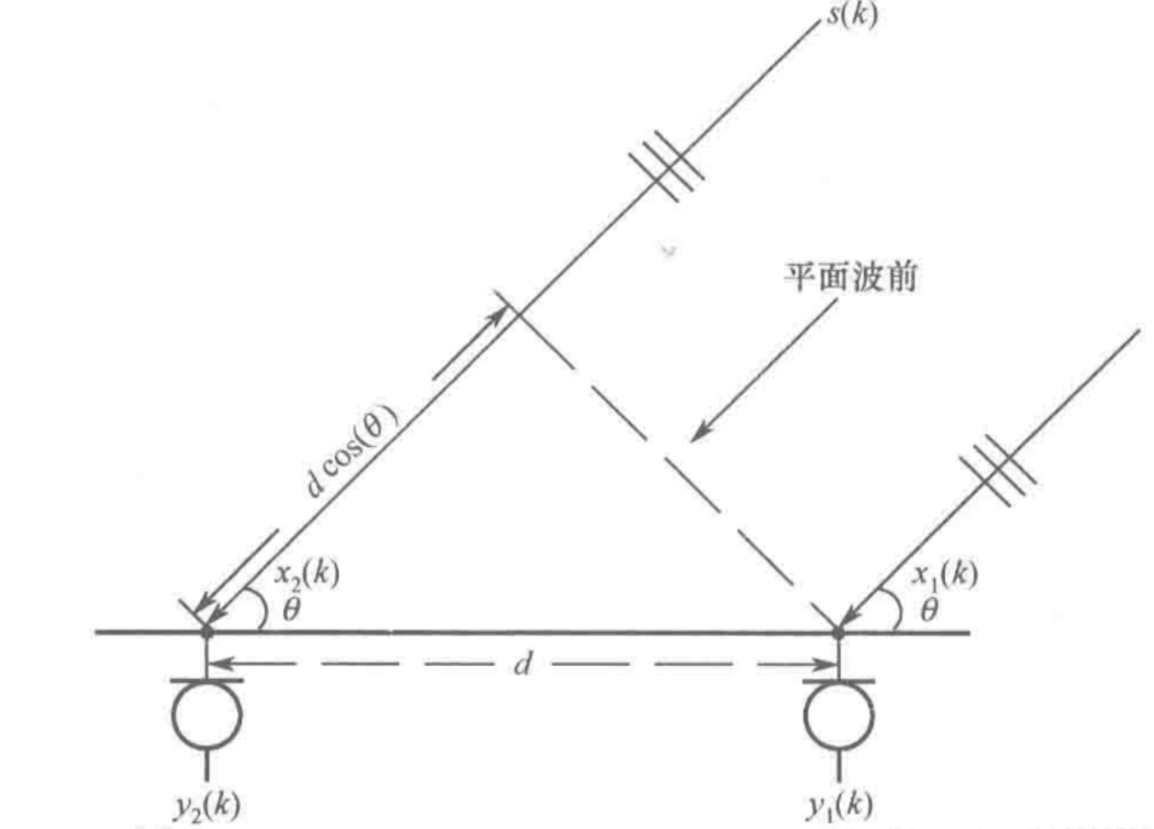
基于相对时延估计的方法利用麦克风阵列的几何排列,捕捉不同麦克风接收到信号的时间差异。通过计算这些时间差,并采用互相关、广义互相关(GCC)或相位差等技术,可以准确测量信号到达时间差(TDOA)。结合麦克风阵列的具体布局,精确推算声源的方位角。这种方法不仅依赖时间延迟的测量,还结合各麦克风的空间位置,实现对声源方向的高度准确估计。选择合适的算法可在复杂环境中提高定位精度和可靠性。
基于波束形成的方法
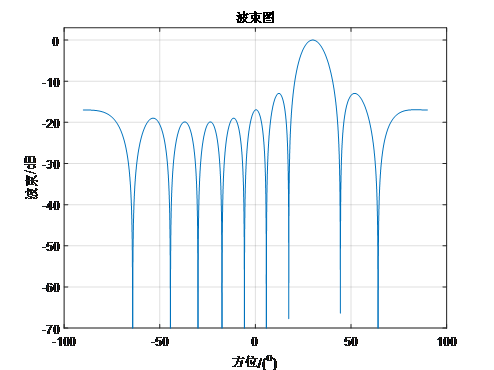
波束形成技术通过调整麦克风阵列中各信号的相位,实现对特定方向的声音聚焦。利用加权求和的方法,可以确定波束输出功率最大的方向,进而精确定位声源。常见的波束形成算法包括:
延迟相加(DS):通过对不同麦克风接收的信号施加适当的延迟后相加,增强特定方向的声音。
最小方差无失真响应(MVDR):优化权重以最小化输出信号的方差,同时保持对目标方向的无失真响应。
可控响应功率相位变换法(SRP-PHAT):通过分析信号的相位信息来提高定位精度,特别适用于多路径环境。
这些算法各有特点,适用于不同的应用场景和技术需求。
基于信号子空间的方法
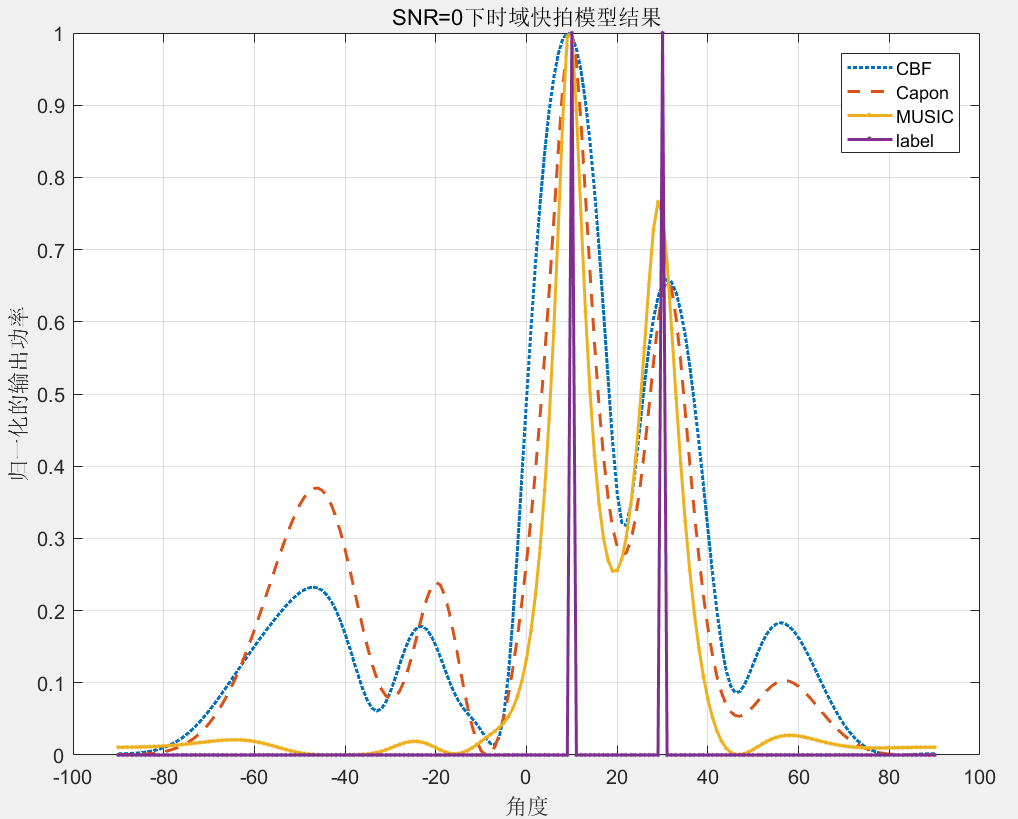
信号子空间方法分为两种:非相干和相干。非相干(如MUSIC):通过特征值分解区分信号与噪声子空间,生成高分辨率谱图。宽带信号经傅立叶变换分解为窄带,分别处理后合并结果。相干:集中信号到参考频率,使用窄带技术估计方位,适合相位一致的多通道信号。这两种方法分别适用于不同类型的信号源定位。
基于深度学习的方法
基于深度学习的声源定位算法利用神经网络强大的特征提取和模式识别能力,直接从原始音频数据或其变换域表示中学习声源位置。这类方法通常不需要显式的物理模型,而是依赖于大量的训练数据来自动学习声源定位的相关特性,映射出定位结果。这种方法分为基于网格和无网格两大类,它们在定位精度和声源数量估计方面各有优势。