
主动说话人检测(ASD)
定义
主动说话人检测 (ASD: Active speaker detection) 的目标是检测视觉场景中谁正在说话,它需要处理快速变化的说话场景,进行视频帧级别的预测。ASD是很多应用的重要前端,比如语音识别、语音分离 、说话人跟踪等。
研究发展
人通常如何判断一个人是否正在说话,主要因素包括以下3点:
1. 感兴趣的音频是否属于人声?
2. 感兴趣的人的嘴唇是否在运动?
3. 如果1、2成立,语音与嘴唇运动是否同步?
基于这一事实,很自然想到的是使用语音和视觉这两种模态来共同判断说话活动。ASD的研究从早期的单模态逐步发展到多模态,从短时序发展到长时序特征建模,可概括为5个阶段:
Ø 基于单模态的方法
描述:仅利用单一模态特征(音频或视觉)进行说话人检测,音频特征通过语音活动检 测(Voice Activity Detection,VAD)来判断语音存在性,视觉特征通过分析面部运动来 判断是否在说话。
优点:实现简单,对计算资源要求低。
缺点:单模态信息不全面,可靠性差,音频易受到环境噪声的影响,视觉易受到非说话 动作(如微笑、打哈欠、咀嚼等)的影响。
Ø 基于特征拼接的方法
描述:直接将音频特征和视觉特征进行简单拼接,然后通过简单的分类器(如多层感知 机,MLP)进行检测。
优点:结合了音频和视觉特征,有效提升了检测准确性。
缺点:忽略了音频和视觉之间的信息交互,只能处理静态图片特征。
Ø 基于RNN结构的方法
描述:利用RNN、LSTM或者GRU这种递归神经网络结构,对音频和视觉的时序上下文特征进行建模,捕捉时序上的动态变化。
优点:引入了时序信息,能够对音频和视觉的动态变化进行建模。
缺点:基于RNN结构的网络对于长时序特征的提取能力不足,依然忽略了音频和视觉 之间的信息交互。
Ø 基于短时序的多模态方法
描述:提取短时段内(200ms~600ms)的音频特征和视觉特征,基于Transformer的交叉 注意力机制和自注意力机制,进行多模态特征交互和同步。
优点:引入了跨模态特征间的信息交互。
缺点:时间窗口过短,无法完整捕捉说话活动。
Ø 基于长时序的多模态方法
描述:从更长的时间段内(> 2秒)提取音频特征和视觉特征,基于Transformer的交叉注意力机制和自注意力机制,进行多模态特征交互和同步。
优点:引入长时序的音视频特征,有效提升了检测准确性。
缺点:需要更多的计算资源,无法实时检测。
目前基于长时序特征的多模态方法是该领域的前沿(比如TalkNet、Light-ASD),通过多模态信息的交互和同步,在复杂场景中能表现出更高的鲁棒性。
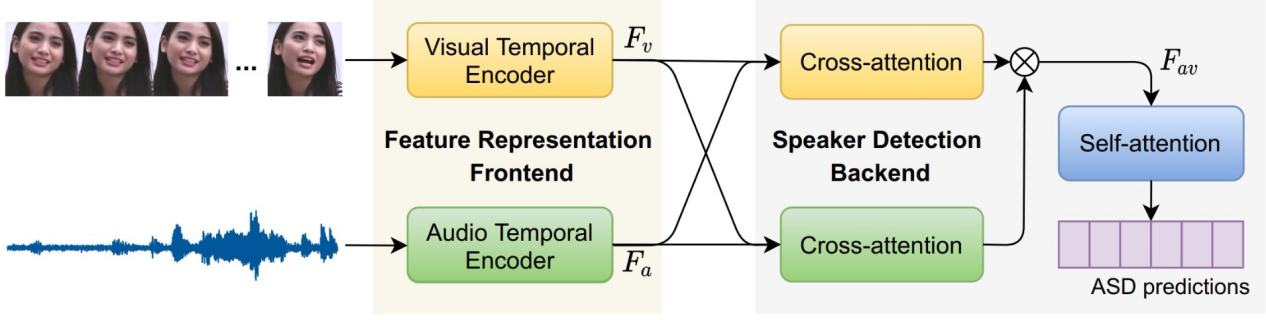
(TalkNet网络结构图)